다변량 ARIMA, MLP 및 LSTM을 활용한 지하수위 결측 처리 비교

초록
국내 설치 운영 중인 지하수 관측정은 계측 센서의 고장 또는 전원 장치의 이상 등으로 결측이 발생하기도 한다. 지하수위 자료를 활용한 수문 평가, 지표수와 지하수의 연계 분석 및 지하수 함양량 산정 등을 위하여 결측 자료의 처리는 필수적이다. 본 연구에서는 가평가평 국가지하수 관측정의 1개월의 지하수위 결측 기간을 채우기 위하여 다변량 ARIMA와 인공신경망 모델인 MLP 및 LSTM을 적용하였으며, RMSE 및 MAE를 활용하여 모델의 정확도를 비교 분석하였다. 자기회귀 특성의 지하수위와 인근의 강우 자료가 입력변수로 사용되는 다변량 ARIMA 및 LSTM 모델이 MLP 모델에 비하여 정확한 것으로 평가되었다. LSTM 모델의 경우, 입력 변수로 사용되는 주변 강우 및 지하수 관측정의 수를 증가하더라도 오차가 거의 줄어들지 않는 것으로 나타났다. LSTM 모델은 훈련 및 검증 자료에 의하여 결정되는 만큼, 지하수위 결측 처리의 일관성을 위해서 입력 변수의 선정 방법에 대한 추가 연구가 수행될 필요가 있다.
Abstract
Groundwater monitoring wells in this country may have missing values due to a malfunction of sensor or an abnormal power supply. Processing of missing values is essential for hydrological assessment using groundwater level time series, interaction analysis between surface and ground water, and estimation of natural recharge rate. In this study, multivariate ARIMA and artificial neural network models (MLP and LSTM) are applied to fill the one-month missing period of groundwater levels at the Gapyung-gapyung (GPGP) monitoring station, and the accuracy of the models is compared based on RMSE and MAE. The multivariate ARIMA and LSTM models, which use both groundwater level data of autoregressive properties and nearby rainfall data as input variables, are evaluated to be more accurate than the MLP model. It is found that the error of the LSTM model is hardly decreased even if the number of rainfall and groundwater monitoring stations increases. As the LSTM model depends on the training and validation data, further studies on the method of selecting input variables need to be conducted for the consistency of missing value imputations.
Keywords:
groundwater level, missing value, multivariate ARIMA, MLP, LSTM키워드:
지하수위, 결측, 다변량 ARIMA, MLP, LSTM1. 서 언
2017년 현재 국내에는 중앙정부, 지방자치단체 및 공공기관 등에서 약 2,283개의 지하수 관측정이 있으며 이 중에서 80% 이상이 자동 계측 방식으로 운영 중에 있다(MOLIT, 2017). 일반적으로 매 1시간마다 지하수위, 온도 및 전기전도도 등을 측정하고 있으며, 계측장비의 노후화 및 점검과 같은 외부로부터의 자극 등으로 인하여 결측이 발생하기도 한다. 수 시간의 단기간 결측 뿐 아니라 수 주 이상의 장기간 결측이 발생하는 경우, 데이터의 활용 측면에서 결측에 대한 사후 처리가 요구된다. 지하수위 결측의 존재는 지하수의 장기 추세 평가 및 인위적인 지하수위 변동성 평가 등과 같은 지하수위를 활용한 분석에 오류를 발생시킬 수 있으므로, 신뢰성 높은 결측값 대체가 필요하다.
지하수위 결측 처리를 위한 연구로서, 피크형의 지하수위 변동을 보이는 자료에 대하여 크리깅과 조건모사에 의한 결측 처리(Chung, 2011), 인공신경망(ANN, Artificial neural network) 및 기계학습 기법 기반의 지하수위 변동 시계열 예측 모델을 활용한 데이터 처리(Yoon et al., 2016) 등이 수행된 바 있다. 전세계적으로 인공신경망을 활용한 지하수위 시계열 예측 기법들이 연구되고 있으며(Daliakopoulos et al., 2005; Banerjee et al., 2009), 최근에는 LSTM 모델을 활용한 농업 지역에서의 지하수위 예측(Zhang et al., 2018), 해안 홍수 취약 지역에서의 지하수위 예측을 위한 LSTM 및 RNN 활용 연구(Bowes et al., 2019), 인공신경망과 연계하여ARIMA, Fuzzy 및 Bayesian network 등을 융합한 다양한 시계열 하이브리드 모델이 개발되고 있다(Moghaddam et al., 2019; Nadiri et al., 2019).
본 연구에서는, 시계열 분석 기법인 다변량 ARIMA에 의한 지하수위 결측 처리 기법과 인공신경망 기법으로서 MLP (Multi-layer Perceptron) 및 LSTM (Long short-term memory)를 활용한 결측 처리 기법을 비교 검토하고, 그 적용성을 제시하고자 하였다.
2. 연구 방법
2.1 다변량 ARIMA
Box-Jenkins 모델은 시계열 분석에 다양하게 활용되는데 대표적으로 자기회귀누적이동평균(ARIMA, Auto-Regressive Integrated Moving Average) 모델화 방법으로서, 모델 식별, 추정, 진단, 예측의 단계를 통하여 분석이 이루어진다. ARIMA의 AR은 관심 변수가 시차 값으로 회귀됨을 나타내는 것으로서 이전의 값이 이후의 값에 영향을 미치는 상태이며, MA 부분은 회귀 오류가 실제로 과거 여러 시간에 동시에 발생한 오류 항의 선형 조합임을 나타낸다. 지하수위 변동은 과거의 지하수위에 의하여 영향을 받는 AR 모델이 기본으로서 자체 데이터를 이용한 단변량 ARIMA 모델에 의하여 예측되기도 한다. 단변량 ARIMA 시계열 모델과 달리, 다변량 ARIMA 시계열은 각각의 입력 변수들이 서로 영향을 미치게 되며, 입력 변수들 사이에 존재하는 상호작용과 동적 관계를 토대로 예측하는 모형으로서, 단변량 ARIMA 모형에 각 입력 변수들간의 교차상관 매트릭스, 편자기상관 메트릭스 등이 고려된다(Tiao and Box, 1981).
다변량 시계열은 다음과 같이 복수의 시계열 y1,...,yk을 갖는 관측값과 평균 0인 미지의 값 벡터(ut)로 표현된다.
다변량 ARIMA 모델은 k×k차원의 상관계수 행렬인 ϕ1,...,ϕp을 갖는 AR 모델 부분과 θ1,...,θq의 MA 모델 부분으로 구성된 다음의 일반식으로 나타낸다.
2.2 MLP
MLP는 입력층과 출력층 사이에 하나 이상의 은닉층이 존재하는 인공신경망의 계층 구조를 말하는 것으로서, 각 층간의 뉴런의 연결강도를 최적의 상태로 적응하는 학습과정을 통하여 최적 모델이 구성된다. 출력 뉴런에 의하여 절단되는 은닉층의 출력은 아래 식과 같이 각 시냅스의 가중치(wij)와 노드의 입력자료(xj)에 의하여 결정된다(그림 1).

Multilayer perceptron concept of an artificial neural network with a hidden layer (Kim and Oh, 2018).
또한, 출력층에서 출력값(yk)는 시냅스의 가중치와 은닉층 및 출력층에서의 활성화 함수(g 및 )에 의하여 결정된다. 본 연구에서는 출력값이 0과 1 사이로 표현되는 시그모이드(sigmoid) 활성화 함수를 사용하였으며, 1개의 은닉층으로 모델을 구성하였다.
2.3 LSTM
일반적인 인공신경망과 달리 RNN (Recurrent neural network)은 은닉층의 결과가 다시 같은 은닉층의 입력으로 들어가도록 연결되는 것으로서 순서와 시간을 고려할 수 있는 모델이다. 그러나, RNN은 순서 자료 간의 거리가 멀어질수록 두 정보간의 연결이 어려워지는데, 역전파 알고리즘의 계산량이 많아지고 전파되는 양이 점차 작아져서 학습능력이 현저히 줄어드는 장기의존성(Long-term dependency)의 기울기 소(Vanishing gradient) 문제가 발생하게 된다. 이를 해결하기 위하여 기존 RNN에 cell state를 추가하여 먼 과거의 데이터의 특성을 얼마나 반영할 것인지를 제어할 수 있는 LSTM이 고안되었다(그림 2; Hochreiter and Schmidhuber, 1997). LSTM 모델은 기상, 하천, 지하수위, 주식 등과 같이 과거의 특성을 활용하여 미래를 예측하는 분야에 많은 연구가 이루어지고 있다(Zhang et al., 2018; Le et al., 2019; Poornima and Pushpalatha, 2019).

The repeating module of an LSTM with four interacting layers (revised from http://colah.github.io/posts/2015-08-Understanding-LSTMs/ by Olah, C.).
LSTM은 cell state로부터 과거의 어떤 정보를 버릴 것인지 결정하는 “forget gate layer”, 새로이 들어오는 정보 중 어떤 것을 cell state에 저장할 것이지 정하는 “input gate layer”, 새로운 후보값 벡터를 결정하는 “tanh layer”, 이들 값을 이용하여 과거 cell state를 업데이트하는 “cell state update”, 마지막으로 출력으로 내보낼 값을 정하는 “output gate layer”로 구성이 된다(그림 2).
본 연구에서는 모델 훈련시 적용된 Batch의 학습 상태가 다음 Batch에 전달되도록 하는 상태유지(Stateful) 및 이 상태유지가 누적되어 쌓이도록 하는 상태유지 스택(Stateful stack) LSTM 모델을 적용하였다. 사용된 자료는 Minmaxscaler를 사용하여 표준화 하였으며, 모델은 3개의 층으로 구성하였고, window 크기는 10, 최적화함수는 RMSprop, 활성화함수는 tanh, 과적합을 방지하기 위하여 Dropout (0.05)를 사용하였다.
3. 분석 자료
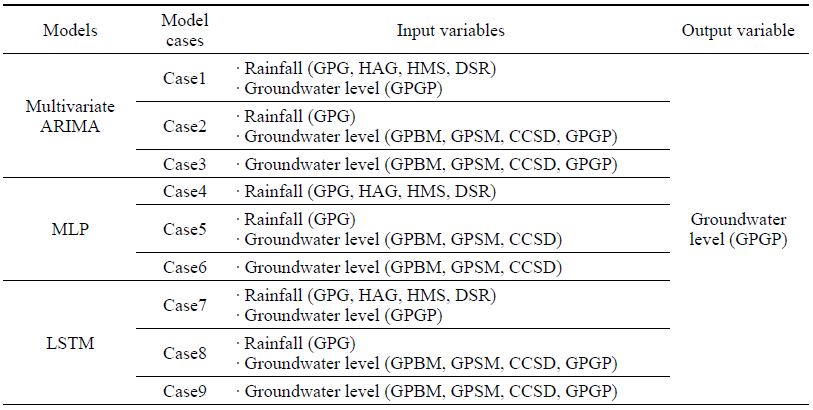
자연 상태의 지하수위는 기본적으로 강우와 과거 지하수위에 의하여 영향을 받는데, 본 연구에서도 모델 구축을 위하여 주변의 강우 및 지하수위 자료를 입력 변수로 활용하였다. 결측 예측을 위한 출력 변수로 사용된 지하수위는 가평가평(GPGP) 지하수 관측정의 2013년부터 2017년까지 5년간의 일 평균 자료로서, 2017년 6월을 결측 기간으로 설정하고 모델을 적용하도록 하였다. 다변량 ARIMA는 과거 데이터의 정보를 토대로 미래 시계열이 생성된다는 점을 기초로 한 것이므로, 규칙성과 white noise의 특성이 충분히 파악되는 경우에 보다 양호한 예측이 가능한 반면, 인공신경망 모델인 MLP 및 LSTM은 훈련자료와 검증자료에 의하여 모델이 결정되는 특성이 있으므로 충분한 훈련자료의 확보가 필요하다. 인공신경망 모델은 2013년 1월 1일부터 2016년 2월 2일까지 훈련기간으로 설정하고 2016년 2월 3일부터 2017년 5월 31일까지 검증기간으로 설정하여 7:3 정도로 구성하였다. 모델의 입력 변수로서 주변의 강우 4개소 및 지하수 관측정 3개소의 동 기간의 자료를 수집하여 활용하였다(강우 : 가평교(GPG), 화악교(HAG), 하면사무소(HMS), 대성리(DSR), 지하수 관측정 : 가평북면(GPBM), 가평상면(GPSM), 춘천신동(CCSD)) (표 1; 그림 3).

Input and output variables used for the model construction.

Location of the study area and the rainfall and groundwater observation stations.
가평가평 관측정은 계절변동과 강우에 대한 반응 peak를 잘 보이는 특성을 갖고 있으며, 가평북면 및 춘천신동은 계절변동 특성은 약하나 강우에 대한 반응을 잘 보이는 특성을 보이며, 가평상면은 계절변동은 보이나 강우에 대한 빠른 peak 특성이 잘 나타나지 않고 있다. 가평가평은 국가지하수관측망의 지하수위에 대한 주성분 분석에서 도출된 대표 주성분의 특성과 유사하여 우리나라의 강우에 의한 전형적인 지하수위 변동 특성을 보여주고 있으며, 가평상면의 경우에도 주성분 분석에서 도출된 두 번째 주요 성분으로 잘 설명되는 지역이다(그림 4, 5; Kim and Yum, 2007). 한편, 가평가평 지하수 관측정 주변의 4개 지점 강우량의 변동 양상은 지점별로 큰 차이를 보이지 않고 있다(그림 4).

Time series of groundwater levels at the monitoring wells (a, b, c, d) and rainfalls (e, f, g, h) from 2013 to 2017.

Two principal components of groundwater levels in South Korea proposed by Kim and Yum (2007).
4. 연구 결과
4.1 각 모델별 특성 비교
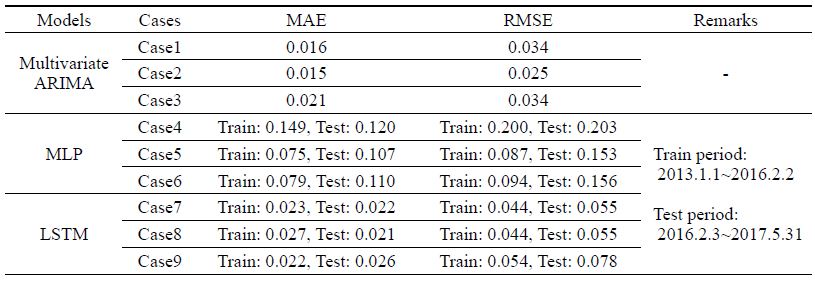
상기 3개 방법의 적용성 비교를 위하여 강우와 지하수위로 구성된 9가지 입력 변수 조건에 대하여 모델을 구성하였다(표 1 참조). 평균절대오차(MAE) 및 평균제곱근오차(RMSE)를 활용하여 실측값과 예측값의 오차를 평가한 결과, 다변량 ARIMA 및 LSTM 모델이 MLP 모델에 비하여 정확한 것으로 나타났다(표 2). 이 결과는 두 모델은 가평가평 지하수위 자료가 입력 변수로도 사용되어 지하수위의 자기회귀 특성이 모델에 반영되었기 때문이다. 다변량 ARIMA와 LSTM 모델을 비교하면 다변량 ARIMA 모델이 보다 정확한 것으로 평가되나 그 차이는 크지 않으며, 다변량 ARIMA 모델은 각 Case 별 오차의 편차가 LSTM에 비하여 큰 것으로 나타나, 모델 입력 자료에 의존성이 큰 것으로 평가된다.
Results of prediction error for the multivariate ARIMA, MLP, and LSTM models.
다변량 ARIMA 모델 중에는 가평교 관측소의 강우량과 주변 지하수 관측정의 지하수위가 입력 인자로 사용된 Case 2의 오차가 가장 작은 것으로 나타났는데, 지하수위 변동이 강우량과 밀접한 관련이 있는 특성이 반영된 것으로 보인다. 반면에, 주변 지하수 관측정의 지하수위 자료들을 입력 인자로 활용한 Case 3은 오차가 상대적으로 큰데, 이는 주변 지하수 관측정의 지하수위가 가평가평 관측정의 지하수위와 특성이 일치하지 않고 변동 유형이 다르며 시차간 연결성이 작기 때문으로 보인다.
한편, MLP 모델의 예측 오차가 상대적으로 큰 것은 시기별 데이터간의 자기회귀성 특성이 학습에 사용되지 않았기 때문이다. MLP 모델에서의 입력 인자의 중요도를 보면, 강우 자료만으로 학습된 Case 4의 경우는 각 관측 지점이 0.22 ~ 0.28 정도의 중요도로서 큰 차이를 보이지 않고 있다(그림 6). 가평교 강우와 주변 3개 지하수 관측정 수위로 학습된 Case 5 및 지하수 관측정 수위로만 학습된 Case 6의 경우는 가평상면이 0.46 및 0.53으로 가장 높은 중요도를 보인다. 이는 가평가평과 가평상면이 유사한 계절 변동을 갖기 때문에 가평상면의 데이터 특성과 학습효과가 가평가평 지하수위를 결정하는데 상대적으로 크게 작용하게 된 것이다.

Predictors importance of three MLP models.
가평가평 관측정은 굴착 깊이가 약 130 m 깊이로서 54 ~ 70 m 구간에 스크린이 설치되어 있으며, 상부 7.5 m 정도의 미고결층을 갖는다. 인근 하천으로부터 약 410 m 떨어져 있고 하천보다 약 50 m 높은 위치에 설치되어 하천의 영향을 거의 받지 않는 지점으로서 전형적인 계절변동과 강우시 상승 반응이 잘 나타나는 시계열 특성을 보이고 있다. 상기 분석 결과를 종합하면, 1개소의 강우 자료와 주변 3개소 지하수 관측정 수위 자료 및 가평가평 관측정의 과거 수위자료가 주 입력 변수로 사용되는 Case 2, 5 및 8의 정확성이 나머지 Case에 비하여 결측 구간 예측력이 우수한 것으로 나타났다. 이는 인근의 강우와 지하수위 자료를 학습시키는 것이 관측 지점의 지하수위 예측에 활용될 수 있음을 보여준다.
4.2 예측 결과 비교
각 모델별로 우수한 예측 성능을 갖는 Case 2, Case 5 및 Case 8 조건에 대하여 2017년 6월의 지하수위를 예측하고 실제 계측 자료와 비교하였다(그림 7). 그림에서 보는 바와 같이, MLP 보다는 다변량 ARIMA와 LSTM 모델이 결측을 처리하는데 유용한 것으로 보인다. 또한, 다변량 ARIMA에서는 6월 초기 예측은 양호하나 하순으로 갈수록 오차가 증가하며 7월 실측값과의 연결성이 떨어지는 특성을 보이는 반면, LSTM 모델은 예측 기간 중 6월 초중순의 값이 다변량 ARIMA 보다 부정확하나 7월의 실측값과의 연결은 보다 자연스러운 것으로 나타났다.

Application of the prediction models to fill the missing period from June 1 to 30 in 2017.
5. 토 의
위 결과에서 보듯이 지하수위의 예측을 위하여 다변량 ARIMA 또는 LSTM 모델이 사용가능 한 것으로 파악되었으며, 특히 LSTM 모델의 경우에는 입력 변수의 종류에 따른 모델간의 오차의 편차가 작으며, 결측값 예측시 전후 자료와의 연결성도 양호한 것으로 파악되었다. 한편, 모델 입력 변수의 조건을 보다 다양하게 적용하여 LSTM 모델의 적용성과 정확성을 추가적으로 검토해 보았다(그림 8).

Distribution of RMSE and MAE of train and test data for 16 simulations with different input variables: (a) multi-rainfalls (GPG, HAG, HMS, DSR) and GPGP, (b) rainfall (GPG) and groundwater (GPGP, GPBM, GPSM, CCSD), (c) single rainfall (GPG, HAG, HMS, DSR) and GPGP, (d) rainfall (HAG) and groundwater (GPGP, GPBM, GPSM, CCSD) and (e) groundwater (GPGP, GPBM, GPSM, CCSD).
가평가평 지하수 관측정 주변에 4개의 강우 관측소가 위치하는데 1개 강우 자료를 입력변수로 사용하는 경우와 여러 개를 사용하는 경우의 모델을 비교해 보면, 강우 관측소가 증가하더라도 RMSE 및 MAE의 감소는 거의 발생하지 않음을 알 수 있다(그림 8a). 또한, 가평가평 지하수 관측정에 최인접한 가평교 관측소의 강우량과 주변의 지하수 관측정을 조합한 경우에는 지하수 관측정의 갯수를 증가시키더라도 오차의 뚜렷한 감소는 나타나지 않는다(그림 8b). 주변에 있는 4개 강우 관측소를 하나씩 번갈아가면서 입력 변수로 사용한 경우에는 오차에 약간의 변동이 존재하는데, 화악교 관측소의 강우량을 입력 변수로 활용한 경우가 가장 큰 오차를 보이는 것으로 나타났다. 이는 화악교 관측소가 가평가평 지하수 관측정과 비교적 원거리에 위치한다는 점과 우리나라의 주된 강우 이동 방향을 고려할 때 북동쪽에 위치한 화악교 지점의 강우가 가평가평 관측정의 지하수위에는 큰 영향을 미치지 못한다는 점이 작용하는 것으로 보인다(그림 8c). 가평가평 관측정에 최인접한 가평교 강우 관측소가 아닌 북동 방향에 위치한 화악교 강우 관측소를 활용하여 상기 두번째 조건과 동일하게 적용한 경우에는 가평교를 활용한 경우보다 화악교를 활용한 경우가 좀 더 큰 오차를 보인다(그림 8d). 한편, 주변에 위치한 3개 지하수 관측정의 지하수위 자료만을 입력 변수로 활용하여 가평가평 관측정의 지하수위를 예측한 결과, 강우를 포함한 경우보다 오차가 훨씬 크게 나타났다(그림 8e).
이상 결과를 정리하면, 지하수위 결측 자료의 처리를 위해서는 그림 8의 입력변수 조건 1에 해당하는 인접한 강우량(가평교)과 자기 자신의 지하수위(가평가평) 자료를 이용한 LSTM 모델을 구축하는 것만으로도 좋은 결과를 도출할 수 있으며, 보다 정확성을 높이기 위해서는 주변의 지하수위 자료를 함께 활용하는 것이 필요한 것으로 평가되었다.
6. 결 언
지하수위 시계열 자료는 기후변화에 따른 수문 환경 변화의 평가, 지표수와 지하수의 상호작용의 이해, 지하수 함양량 및 개발가능량의 산정 등 다양한 분야에 활용된다. 지하수면 아래에 설치되는 지하수위 자동 계측 장치는 수압 및 누수에 의한 고장, 전원의 불안정 및 오류로 인한 문제 등으로 결측을 발생시킬 수 있다. 본 연구에서는 이와 같은 지하수위 결측 처리 방법으로서 다변량 ARIMA, MLP 및 LSTM 모델을 적용하였는데, 다변량 ARIMA와 LSTM 모델의 정확성이 높은 것으로 나타났으며, 각 방법 공히 인근의 강우자료와 지하수위 자료를 동시에 입력변수로 활용한 모델이 지하수위를 예측하는데 보다 정확한 것으로 나타났다. 이와 같은 결과는 지하수위 변동이 자기회귀 특성과 강우에 의한 반응 특성을 모두 포함하기 때문으로 보인다. LSTM 모델은 과거의 정보를 현재 및 미래 예측에 활용할 수 있다는 장점이 있는 반면, 인공 신경망 모델의 특성상 훈련자료에 의한 영향을 많이 받기 때문에 보다 정확하고 실용성 있는 지하수위 예측 모델을 구축하기 위해서는 훈련 및 검증에 사용되는 입력 변수를 어떻게 결정할 것인가에 대한 추가 연구를 지속적으로 시행해 나갈 필요가 있다.
Acknowledgments
본 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단의 지원을 받아 수행된 연구임(No. NRF-2019R1A2C1088085).
References
-
Banerjee, P., Prasad, R.K. and Singh, V.S., 2009, Forecasting of groundwater level in hard rock region using artificial neural network. Environmental Geology, 58, 1239-1246.
[https://doi.org/10.1007/s00254-008-1619-z]
-
Bowes, B.D., Sadler, J.M., Morsy, M.M., Behl, M. and Goodall, J.L., 2019, Forecasting groundwater table in a flood prone coastal city with Long Short-term Memory and Recurrent Neural Networks. Water, 11, 1098.
[https://doi.org/10.3390/w11051098]
- Chung, S.Y., 2011, Interpolation of missing data in groundwater-level distributions with peak type variations at a national groundwater monitoring well. Journal of the Geological Society of Korea, 47, 277-288 (in Korean with English abstract).
-
Daliakopoulos, I.N., Coulibaly, P. and Tsanis, K.I., 2005, Groundwater level forecasting using artificial neural network. Journal of Hydrology, 309, 229-240.
[https://doi.org/10.1016/j.jhydrol.2004.12.001]
-
Hochreiter, S. and Schmidhuber, J., 1997, Long short-term memory. Neural Computation, 9, 1735-1780.
[https://doi.org/10.1162/neco.1997.9.8.1735]
- Kim, G.B. and Oh, D.H., 2018, Determination of the groundwater yield of horizontal wells using an artificial neural network model incorporating riverside groundwater level data. Journal of Engineering Geology, 28, 583-592 (in Korean with English abstract).
- Kim, G.B. and Yum, B.W., 2007, Classification and characterization for water level time series of shallow wells at the national groundwater monitoring stations. Journal of Korean Society of Soil and Groundwater Environment, 12, 87-97 (in Korean with English abstract).
-
Le, X.H., Ho, H.V., Lee, G. and Jung, S., 2019, Application of long short-term memory (LSTM) neural network for flood forecasting. Water, 11, 1387.
[https://doi.org/10.3390/w11071387]
-
Moghaddam, H.K., Moghaddam, H.K., Kivi, Z.R., Bahreinimotlagh, M. and Alizadeh, M.J., 2019, Developing comparative mathematic models, BN and ANN for forecasting of groundwater levels. Groundwater for Sustainable Development, 9, 100237.
[https://doi.org/10.1016/j.gsd.2019.100237]
- MOLIT (Ministry of Land, Infrastructure and Transport), 2017, Revised Plan of National Groundwater Management. Sejong, 185 p (in Korean).
-
Nadiri, A.A., Naderi, K., Khatibi, R. and Gharekhani, M., 2019, Modelling groundwater level variations by learning from multiple models using fuzzy logic. Hydrological Sciences Journal, 64, 210-226.
[https://doi.org/10.1080/02626667.2018.1554940]
- Olah, C., http://colah.github.io/posts/2015-08-Understanding-LSTMs, / (July 10, 2020).
-
Poornima, S. and Pushpalatha, M., 2019, Prediction of rainfall using intensified LSTM based recurrent neural network with weighted linear units. Atmosphere, 10, 668.
[https://doi.org/10.3390/atmos10110668]
-
Tiao, G. and Box, G., 1981, Modeling multiple time series with applications. Journal of the American Statistical Association, 76, 802-816.
[https://doi.org/10.1080/01621459.1981.10477728]
-
Yoon, H., Yoon, P., Lee, E., Kim, G.B. and Moon, S.H., 2016, Application of machine learning technique-based time series models for prediction of groundwater level fluctuation to national groundwater monitoring network, 2020, data. Journal of the Geological Society of Korea, 52, 187-199 (in Korean with English abstract).
[https://doi.org/10.14770/jgsk.2016.52.3.187]
-
Zhang, J., Zhu, Y., Zhang, X., Ye, M. and Yang, J., 2018, Developing a long short-term memory (LSTM) based model for predicting water table depth in agricultural areas. Journal of Hydrology, 561, 918-929.
[https://doi.org/10.1016/j.jhydrol.2018.04.065]